
Qu’est-ce que la balise noindex ?
La balise noindex est une balise meta HTML (ou un en-tête HTTP) qui permet d’empêcher l’indexation de la page sur laquelle elle est posée par les moteurs de recherche.
Elle se présente comme ceci :
<meta name=”robots content=”NOINDEX”>
Empêcher l’indexation de pages web
La balise noindex permet d’empêcher l’indexation par les moteurs de recherches. Et donc, la prochaine fois que les robots d’exploration passeront sur le site web et détecteront la balise ou l’en tête “noindex”, ils l’excluront des résultats de recherche.
Ainsi, la page ne sera plus visible sur les résultats de Google ou de Bing mais via l’URL, la page sera toujours accessible sans problème.
Balise meta ou en-tête HTTP
La balise noindex peut être implémentée de deux manières :
- via une balise meta HTML
- via en-tête HTTP
La balise meta est plus simple à mettre en place directement dans le code HTML de la page. En revanche, l’en-tête HTTP s’applique à tous les types de fichiers, pas seulement aux pages HTML. Sa mise en œuvre nécessite cependant un accès au serveur web. Le choix entre ces deux méthodes dépend donc des accès que vous avez à votre site.
Pourquoi utiliser la balise noindex ?
Il existe plusieurs raisons pour lesquels utiliser la directive no index :
Éviter le duplicate content
La balise noindex est un outil efficace pour éviter le contenu dupliqué. Elle permet d’exclure de l’indexation les pages ayant un contenu similaire ou identique à d’autres pages déjà indexées.
Par exemple, on peut l’utiliser sur les pages de catégories avec pagination ou les pages de produits avec des variantes mineures. Cela aide à concentrer l’attention des moteurs de recherche sur le contenu unique et pertinent, améliorant ainsi le référencement global du site. Vous préservez ainsi votre crawl budget.
Il y a souvent un débat entre l’implémentation d’une balise no index ou d’une balise canonique pour éviter le duplicate content.
Protéger les pages sensibles
La balise noindex permet de protéger les pages confidentielles ou en développement. En empêchant leur indexation, cela réduit le risque que ces pages apparaissent dans les résultats de recherche. Cette méthode est particulièrement utile pour les pages d’administration, les zones de test, ou les contenus temporaires qui ne doivent pas être accessibles au grand public via les moteurs de recherche.
Comment implémenter la balise noindex ?
→ Introduire les méthodes d’implémentation de la balise noindex. (40 mots)
Avec la balise meta
En utilisant la balise meta, vous devez implémenter le code ci-dessous dans la balise <head> de votre page html (la page que vous souhaitez mettre en noindex).
<head>
<head>
<meta name="robots" content="noindex, follow">
<!-- Autres balises meta et éléments head -->
</head>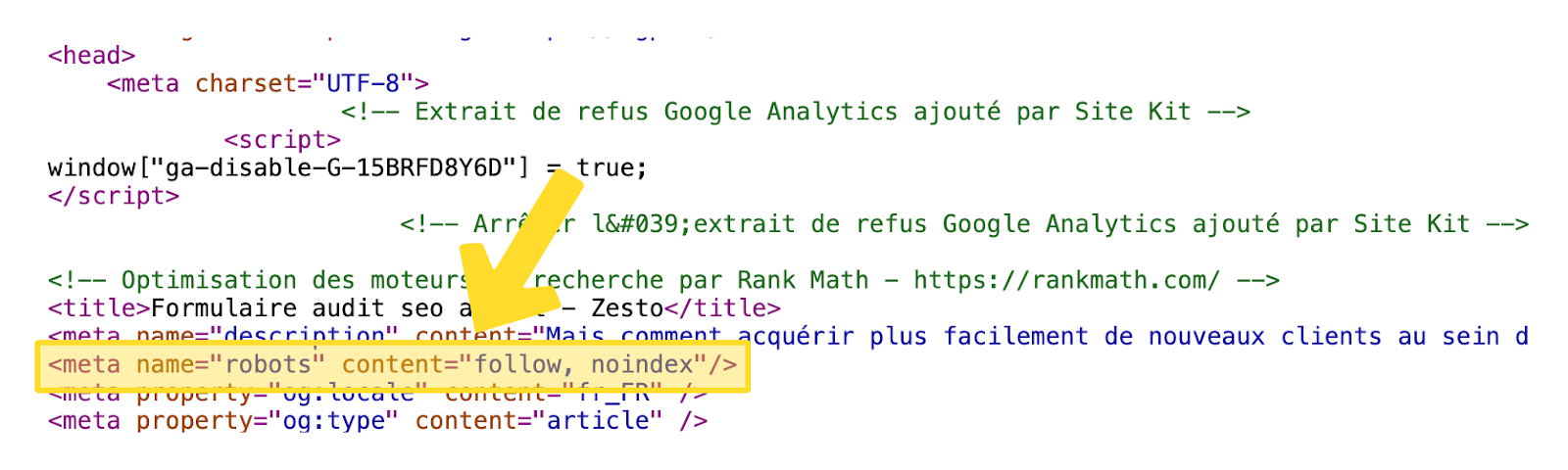
L’attribut name= »robots » indique que l’instruction s’adresse à tous les robots de moteurs de recherche. content= »noindex » demande de ne pas indexer la page, tandis que follow permet aux robots de suivre les liens sortants. On peut remplacer follow par nofollow si nécessaire.
Avec l’en-tête HTTP
L’implémentation via l’en-tête HTTP se fait au niveau du serveur. Voici un exemple pour un serveur Apache (dans le fichier .htaccess) :
<IfModule mod_headers.c>
Header set X-Robots-Tag "noindex, follow"
</IfModule>Pour un serveur Nginx, ajoutez dans la configuration :
add_header X-Robots-Tag "noindex, follow";Cette méthode s’applique à tous les types de fichiers, pas seulement aux pages HTML. Elle est meilleure pour les fichiers PDF ou les images qu’on souhaite exclure de l’indexation.
Vérifier la non-indexation
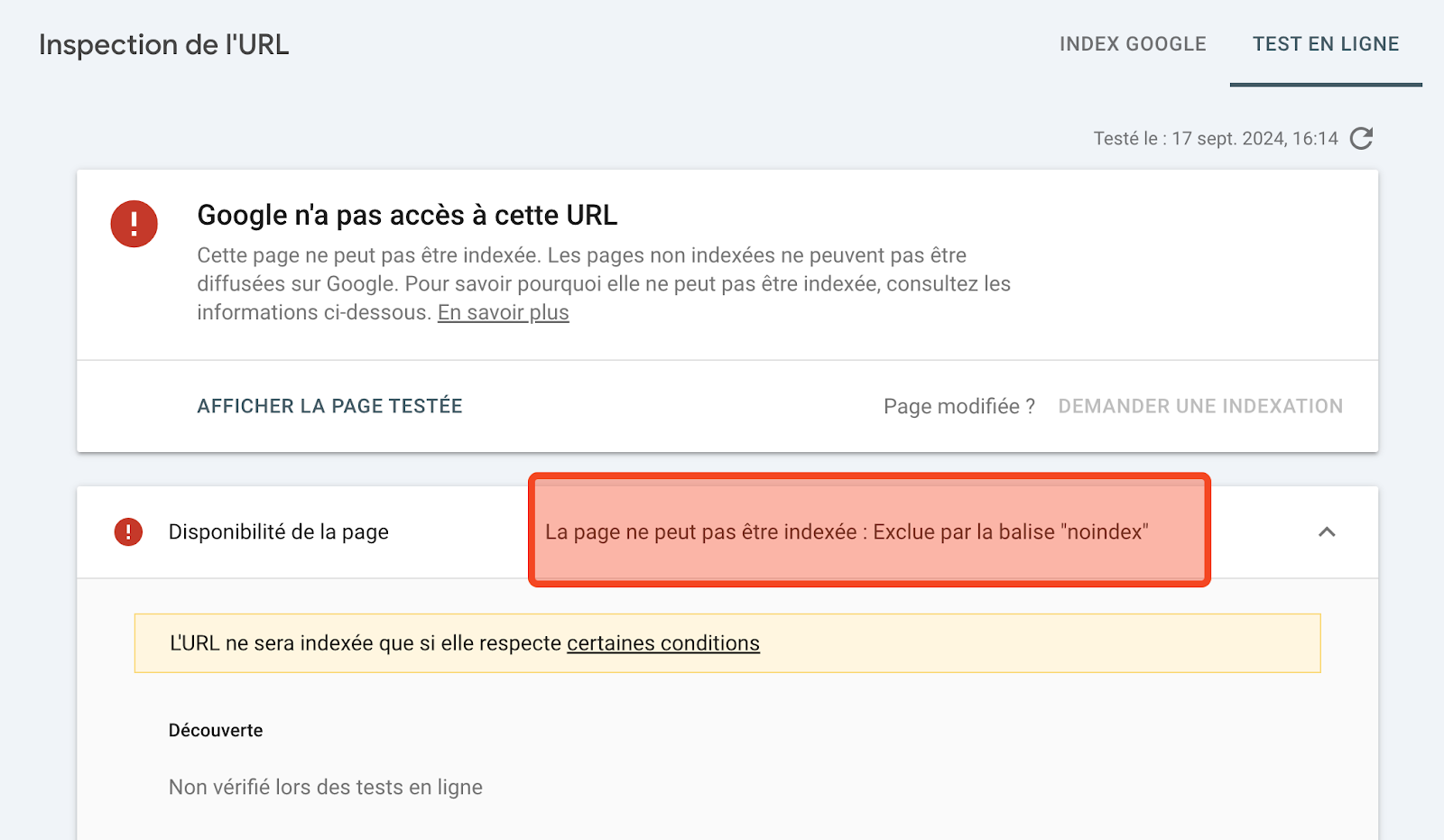
Pour vérifier que la balise noindex fonctionne correctement, utilisez un outil comme la Search Console de Google. La GSC vous alertera si des pages noindex sont indexées. Vous pouvez également utiliser l’outil « Inspecter l’URL » de Google Search Console pour vérifier le statut d’indexation d’une page spécifique. Si une balise noindex est détectée,
Des extensions de navigateur comme « SEO Meta in 1 Click » ou “Detailed SEO” permettent de vérifier rapidement la présence de la balise noindex sur une page.
Les erreurs courantes avec noindex
- Oublier de retirer la balise après une période de développement, empêchant l’indexation de pages importantes.
- Appliquer noindex à l’ensemble du site par erreur, notamment via les robots.txt.
- Combiner incorrectement noindex avec d’autres directives comme index, ce qui peut créer des conflits.
- Ne pas vérifier régulièrement que les pages noindex restent non indexées.
